Understanding k-Nearest Neighbor classifier
Recently, I have started following CS231n MIT Course and the first assignment of week 2 is to implement K-Nearest Neighbors Classifier. This post is introduction to KNN.
Machine Learning
Machine learning algorithms are broadly divided into two categories : Classification/Regression, Clustering. There are supervised and unsupervised learning approaches in each of these categories. Classification category is about identifying a data point and classifying that point into a category. For example., Email can be either Spam/Not Spam. Clustering is about dividing data points into groups/clusters such that points in same group are more similar than the other group.
k-Nearest Neighbors Theory
KNN is a classification algorithm and is considered to be the easiest among all machine learning algorithms(Don’t get confused KNN with K-Means, which is a clustering algorithm). The basic approach in KNN is to consider each data point and place the data point in an n-dimensional space assuming we know each of these point’s grouping category. When we want to categorize an unknown into the groups in KNN, we will calculate the new data point’s distance with each of these points in n-dimensional space and classify the new data point to the one it is nearest to.
For example, consider Apples and Bananas are placed in a plane(based on certain data). Now if a new unknown has to be classified into an Apple or a Banana, we place that element in the same n-dimensional space as that of Apples and Bananas
and find out to which category it’s close to. Now can you say what’s the unknown element in below image is.
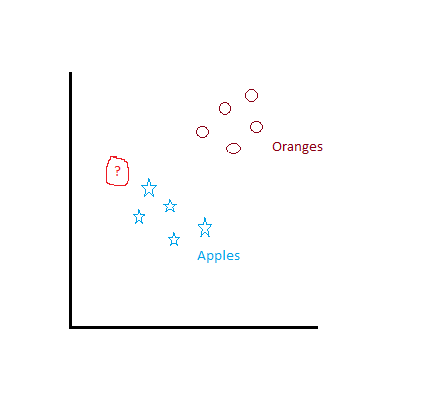
Figure 1: KNN Classification
Now you can ask, I understood Pavan but why is it called K-Nearest Neighbor algorithm but not nearest neighbor algorithm. The answer for that is, instead of searching for one nearest neighbor, the algorithm searches for k nearest neighbors and classifies new data point as the group with majority in those k points.
Nit·ty-Grit·ty
Finding closest point requires to calculate distance between the unknown point and each of the points that we have in n dimensional space. There are two important distance calculation choices: L1(Manhattan Distance) and L2(Euclidean Distance). While L1 distance is simple , L2 distance is .
Pros and Cons
One advantage with KNN is that, it is easy to understand and hence easy to implement. On the flip side, it’s a lazy learning algorithm, I mean all the work is delayed till prediction and require training data to be available during prediction. The other problem is that, as the dimensionality grows, training data requirement grows exponentially.